Или посчитайте файлы в соответствующем каталоге.
# Найти /var/spool/postfix/deferre d-type f | w c-l # Найти /var/spool/postfix/activ e-type f w c-l # Найти /var/spool/postfix/incomin g-type f toile t-l.
Отправьте все сообщения в очередь.
# postqueu e-f # mail q-q # postsupe r-r ALL
Отправить сообщения с определенным идентификатором.
# postqueu e-i # postsupe r-r
Отправить все сообщения для определенного домена.
# postqueu e-s domain. com
Подсчитать количество поставленных в очередь писем с определенным получателем.
# email q | grep bob@domain. com | toile t-l
Показать активных отправителей.
# mailq|grep [A-F0-9] |cu t-c 42-80| sort | uniqu e-c| sor t-n 1 MAILER-DAEMON 1 user1@yahoo. com 33 admin@example. com 1770 no-reply@domain. com
Сортировка сообщений электронной почты по домену отправителя
#mail q | egrep '{w.*d*d*. *@. *. *' --colour|awk ''|cu t-d@ -f2|sort|uni q-c
Из списка почтовых очередей mailq найдите первый номер письма с нужного домена, с которого отправляется большое количество сообщений, и определите имя пользователя, с которого отправляется почта.
# postca t-vq BA84A294E693 | less
Отображает параметры сообщения и причину проблемы с отправкой для определенного идентификатора сообщения в очереди.
# postca t-q BA84A294E693 | less
Аналогичное, но более подробное описание.
# postca t-vq BA84A294E693 | less
Очищает почтовую очередь (удаляет всю почту из очереди).
# postsupe r-d ALL
Очистить очередь отложенной почты.
# postsupe r-d Late
Удалить почту для определенного идентификатора.
# postsupe r-d ID (где ID - идентификатор сообщения)
Удалите почту из очереди в соответствии с ошибкой.
# postqueu e-p | gre p-B1 'Отклонено: домен не найден' | gre p-B1 'Отклонено: домен не найден' | gre p-vE '(--|Rejected)' | awk ' | postsupe r-d - # postqueu e-p | gre p-B1 'Хост Не найден' | gre p-vE '(--|())' | awk '' | postsupe r-d - # postqueu e-p | gre p-B1 'Отклонено: пользователь неизвестен в локальной таблице получателей' | gre p-vE '(--|())' |. awk '' |. postqueu e-vE ' | awk '' - # postqueu e-p |. gre p-B1 'Не удалось завершить вызов проверки отправителя' (--|()' | post supe r-d
В конце сценария можно подставить следующее
Если вы хотите создать пакетное резервирование или ключ
Если вы хотите переслать письмо через очередь. Все зависит от конкретной задачи. Чтобы удалить из очереди письма, отправленные с определенного адреса
# mail q | grep mailer daemon | ah« | cu t-d* -f 1 | xarg s-n 1 postsupe r-d # mailq | grep bob@domain. com | ah» | xarg s-n1 postsupe r-d # postqueu e-p | grep 'mailer daemon' | ah« | postsupe r-d -d - # postqueu e-p | grep „mailer daemon“ | ah» | postsupe r-d - - -.
mailq для определенного получателя/отправителя (поле получателя 8 или поле отправителя 7)
#mail q | tai l-n +2 | gre p-v ' *(' | awk 'BEGIN< RS = "" > < if ($8 == "user@example.com" && $9 == "") print $1 >' | t r-d '*!' | postsupe r-d -d -.
Письмо Postfix «на удержании» (на удержании — Postfix не будет пытаться отправить письмо получателю, находящемуся в таком состоянии).
# postsupe r-h # postsupe r-h ALL
— Все сообщения находятся в состоянии ожидания.
# postsupe r-h Отложено
— Все письма из очереди откладываются в резерв, и письмо отменяется из резерва.
# postsupe r-h # postsupe r-h ALL
— Все письма из очереди переведены в режим ожидания Список писем в очереди для домена получателя Очередь активна.
Время удержания в очереди отказов 1 день (максимальное время, в течение которого письмо считается недоставленным и удерживается в очереди) (по умолчанию: 5 дней)
bounce_queue_lifetime = 3d
Попытка доставить нормальное сообщение в течение 3 дней (максимальное время, в течение которого сообщение будет оставаться в очереди, прежде чем отправитель получит отчет о недоставленных сообщениях) (по умолчанию: 5 дней)
maximal_queue_lifetime = 3d
Минимальный интервал повторной отправки сообщения из очереди (минимальное время между попытками доставки сообщения электронной почты) (по умолчанию: 300 секунд)
minimum_backoff_time = 180 секунд
Максимальный интервал повторной отправки сообщений из очереди (максимальное время между попытками доставить электронное письмо в условиях задержки) (по умолчанию: 4000 секунд)
Максимальное время отката = 6 часов
Период активации менеджера очереди
Дистанционное обучение в сентябре 2021 года: «комбинированное» заменяет «удаленное».
Дистанционное образование в сентябре 2021 года: «комбинированное» заменяет «дистанционное

Здесь планы руководства университетов разнятся. Некоторые университеты утверждают, что при заселении студентов в общежития они требуют подтверждения вакцинации, подтверждения болезни или отрицательного теста ПЦР. Некоторые университеты также утверждают, что никаких ограничений на вход в общежития нет.
Рекомендуется заранее уточнить эту информацию в своем учебном заведении.
Школы переходят на дистанционное обучение с 1 сентября.
Москва и Подмосковье, безусловно, готовятся к обучению в течение всей жизни, ссылаясь на введение с 1 сентября все новых и новых учебных заведений.
Ученики младших классов, вероятно, начнут учиться очно, а что касается старших школьников, то соответствующие российские власти будут «изучать ситуацию», ориентируясь на статистику Covid-19.
К 11 августа официального заявления о переводе старшеклассников на дистанционное обучение сделано не было.
Зачем нужна инструментальная поддержка базового пейджинга
Зачем нужна поддержка инструментов для пейджинга в ключах
Привет всем. Я бэкенд-разработчик, пишу микросервисы на Java + Spring. Я работаю в одной из внутренних команд разработки продуктов Тинькофф.
Я хотел бы перевести небольшую статью Маркуса. В какой-то степени ее можно назвать манифестом. Манифест пытается привлечь внимание к старой, но актуальной проблеме в выполнении SQL-компенсации.

В некоторых местах авторы дополняют его пояснениями и наблюдениями. Все эти моменты называются «примечаниями». По понятным причинам, в
Многие знают, насколько проблематично и медленно манипулировать выбором страниц с помощью смещений. Но знаете ли вы, что это можно легко заменить более эффективной структурой?
Таким образом, ключевое слово offset указывает базе данных пропустить первые n записей в запросе. Однако база данных должна считать эти первые n записей с диска в указанном порядке (обратите внимание: сортировка, если она есть, применяется), и только после этого можно вернуть n+1 и последующие. Самое интересное, что проблема кроется не в конкретной реализации СУБД, а в изначальном определении стандарта.
Строки сначала сортируются, затем ограничиваются путем отбрасывания заданного количества строк из начала … — SQL:2016, часть 2, 4. 15. 3 Производные таблицы (примечание: в настоящее время наиболее используемый стандарт)
Важно отметить, что смещение принимает только один параметр (количество пропускаемых записей). После такого определения СУБД может только получить все записи и отбросить лишние. Очевидно, что такое определение смещения приводит к лишней работе. Неважно, SQL это или NoSQL.
Еще немного боли.
На этом проблемы не заканчиваются. Вот почему. Что произойдет, если новая запись будет вставлена в другой операции, пока с диска считываются две страницы данных?
Пропуск записей с предыдущей страницы с использованием смещения может привести к дублированию в ситуациях, когда новая запись добавляется между чтениями разных страниц (обратите внимание: это может произойти при чтении страницы за страницей с использованием структуры order by. В этом случае новая запись может быть сделана в середине версии).
Диаграмма иллюстрирует эту ситуацию. База данных считывает первые 10 записей, затем вставляется новая запись, и все считанные записи сдвигаются на одну. Затем база данных извлекает новую страницу, содержащую следующие 10 записей, начиная с 11-й, а не с Десятая, дублирующая эту запись. Существуют и другие аномалии, связанные с использованием этого выражения, но эта — самая распространенная.
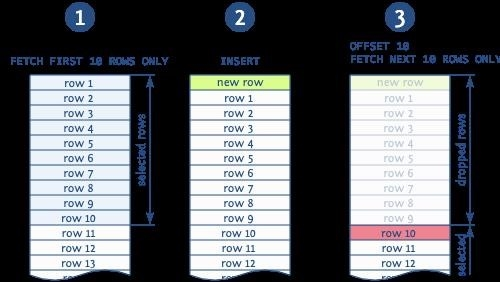
Как уже говорилось, это не проблема конкретной СУБД или ее реализации. Проблема заключается в стандартном определении пагинации SQL. Оно указывает СУБД, какие страницы следует получить и сколько записей пропустить. Поскольку информации о таких запросах слишком мало, база данных просто не может их оптимизировать.
Стоит также уточнить, что это не проблема конкретного ключевого слова, а проблема семантики запроса. Есть несколько других конструкций, которые идентичны с точки зрения проблемы.
Ключевое слово OFFSET, как обсуждалось выше.
А теперь представьте, каким был бы наш мир без всех этих проблем. Оказывается, жизнь без OFFSET не так уж сложна: мы можем использовать условие WHERE только для выбора строк, которые мы еще не видели (примечание: то есть строк, которых не было на последней странице).
Это зависит от того, что выборка выполняется на упорядоченном множестве (старый добрый порядок по). Благодаря упорядоченному набору можно использовать очень простой фильтр для извлечения только данных, начиная с последней записи на предыдущей странице.
Этот подход называется страничной сортировкой по методам поиска или группам ключей. Это решает проблему плавающего вывода (обратите внимание: вышеупомянутое состояние записи между чтениями страниц) и, конечно, быстрее и стабильнее, чем традиционные смещения, которые все так любят. Стабильность заключается в том, что время обработки запроса не увеличивается пропорционально количеству запрашиваемых таблиц (Примечание: Если вы хотите узнать больше о том, как работают различные подходы к пейджингу, посмотрите презентацию автора. Там же можно найти сравнительный бенчмарк различных методов).< ?last_seen_id ORDER BY id DESC FETCH FIRST 10 ROWS ONLY
На одном из слайдов показано, что ключевая подкачка, конечно, не панацея и имеет свои ограничения. Самое главное - ей не хватает способности читать случайные страницы (обратите внимание: она не является последовательной). Однако в эпоху бесконечной прокрутки (примечание: на переднем плане) это уже не так важно. В любом случае, установка номера страницы, на которую нужно нажимать, является плохим решением в дизайне пользовательского интерфейса (примечание: мнение автора статьи).
Подкачка на основе ключевых слов часто не подходит из-за отсутствия поддержки этого метода инструментами. Большинство инструментов роста, включая различные фреймы, не предоставляют возможности для выполнения подкачки.
Ситуация усугубляется тем, что сквозная поддержка технологии, используемой в СУБД, в описанном способе требует выполнения AJAX-запросов в браузере во время бесконечной прокрутки. Вместо того чтобы указывать только номера страниц, необходимо указать набор ключей для всех страниц одновременно.
Однако количество фреймов, поддерживающих пейджинг на основе ключей, постепенно увеличивается. В настоящее время доступны следующие
Если вы используете готовое решение, которое, по вашему мнению, заслуживает поддержки ключевых слов - по возможности, создайте претендента или порекомендуйте готовое решение. Вы также можете обратиться к этой статье.
Причина, по которой простой и удобный подход в качестве ключевого слова не получил широкого распространения, заключается не в том, что он технически сложен в применении или требует больших усилий. Основная причина заключается в том, что большинство людей привыкли видеть и работать со смещениями. Этот подход определяется самим стандартом.
В результате мало кто задумывается об изменении своего подхода к работе с пагинацией. Как следствие, слабо развиты вспомогательные инструменты и библиотеки. Поэтому, если вы подходите к этой идее и у вас есть цель сделать пейджинг без смещений - пожалуйста, помогите!
Николай Малышев о дистанционном образовании в школах и вузах Российской Федерации.